
BIGVOCA Core 편 1~2601 중간점검
- 개발자의 영어공부
- 2022. 9. 15.
모르는 단어가 많아지기 시작했다
모르는 단어가 출현할 때마다 플래그를 붙여서 단어의 위치를 명시했었다. 2000번대를 넘어서니, 이제는 거의 모든 페이지에서 모르는 단어가 출현하기 시작했다. 플래그를 붙이는 의미가 없어졌다. 모르는 단어에는 형광팬으로 색칠을 하기 시작했다.

이렇게 많이 모를줄 몰랐다
영단어 상위 4000개쯤이야 한 번에 금방 훑고 지나갈 수 있을거라 생각했다. 하지만 2601 개까지 보고 나니, 정말 모르는 단어가 많구나라는걸 알 수 있었다. 그동안 독해가 잘 안된다고 느꼈던 이유도 단지 모르는 단어가 많아서일 것이라는 생각이 들었다.

통계를 내보자
다음 표는 256개(16x16) 개의 칸이다. 각 칸에는 10개의 단어 중 모르는 단어의 개수를 넣어봤다. 후반부에 가까이 갈수록 색이 짙어지는 것을 확인할 수 있다.
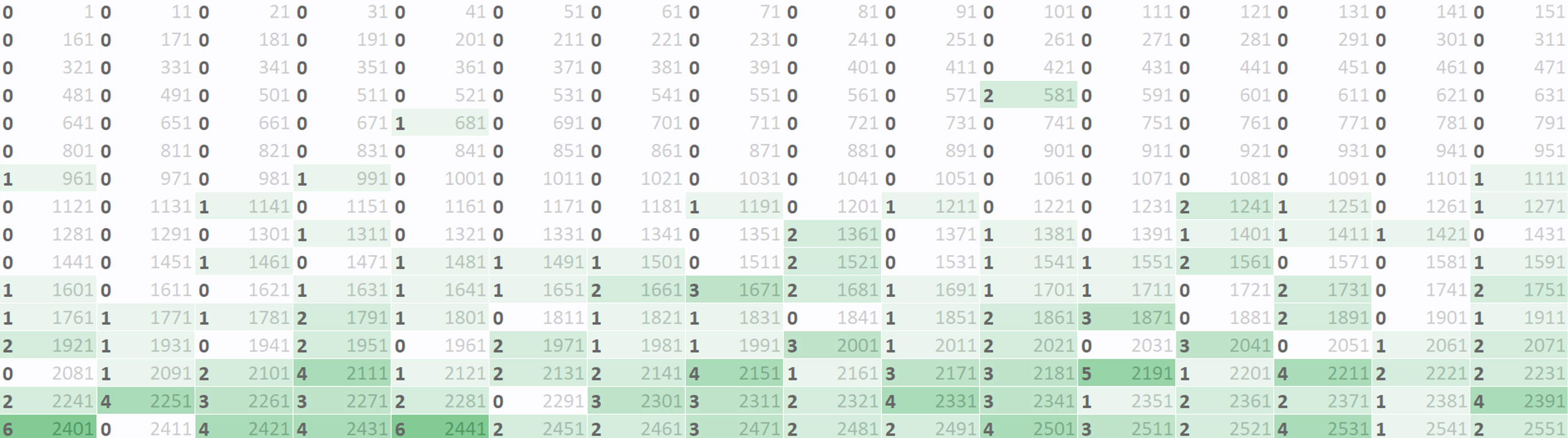
4000개를 모두 끝냈을 때 위처럼 모르는 단어 히트맵을 완성시켜보면 볼만하겠다.

코드
위 히트맵은 엑셀을 활용했는데, 그렇게 하기 위해서는 10개 단위로 모르는 단어의 개수를 csv 로 추출하는 작업이 필요했다. 직접 셀 수도 있었지만 명색이 '개발자의 영어공부' 카테고리에 작성하는 글이므로 간단하고 조악한 코드를 활용해보았다.
먼저 모르는 단어를 정리한 원본데이터는 다음과 같고 공백으로 split(tokenize) 했을 때 첫 번째 요소가 해당 단어의 번호가 된다. 모르는 단어들의 번호를 추출하고, 이 번호들을 순회하면서 해당 번호가 속하는 칸에 +1 을 하는 로직이다.
전략을 변경하자
첫 글에서 밝혔듯이, 이제는 정말 하루에 모르는 단어를 15개씩 찾고, 꾸준히 공부해야 할 것 같다. 남은 단어의 수가 1400개 정도 되므로 남은 단어를 모두 모른다 하여도 94일이면 된다.

'개발자의 영어공부' 카테고리의 다른 글
| BIGVOCA Core 편 2601~2800 (3) | 2022.12.28 |
|---|---|
| 영어를 잘 하기 위해 알고 있어야 하는 단어의 개수 (2) | 2022.09.16 |
| BIGVOCA Core 편 2401~2601 (2) | 2022.09.15 |
| tslint deprecated in favor of eslint (0) | 2022.09.14 |
| 스크럼에서 닭과 돼지란? - Chicken and Pig At Scrum (0) | 2022.09.09 |