
학교에서 알려주지 않는 17가지 실무 개발 기술 Part2 요약
- 개발 서적
- 2022. 3. 26.
💡 필자가 책을 읽고, 몰랐던 부분이나, 특별히 메모할만한 내용을 추출하여 기록한 포스팅입니다. 책 내용 외에 추가 설명을 덧붙인 부분들이 있습니다.
[학교에서 알려주지 않는 17가지 실무 개발 기술] 구매하러 가기 ⬇
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
이전 포스팅(⬇)에서 이어집니다.
[책장파먹기] 학교에서 알려주지 않는 17가지 실무 개발 기술 Part1 요약
8. JSON
8.1. JSON 특징
문자열 인코딩
JSON 규격은 UTF-8 문자열 인코딩만 허용하며, BOM(Byte Order Mark)을 허용하지 않습니다. 따라서, UTF-16(멀티바이트) 환경인 윈도우나 자바, EUC-KR 을 사용하는 환경에서는 JSON 사용에 주의가 필요합니다.
주석
JSON 에서는 주석을 지원하지 않습니다. 따라서, 주석이 필요한 경우 XML, YAML 등의 메시지 규격을 활용해야합니다.
8.2. JSON 구조
키와 값
JSON 에서는 UTF-8 을 인코딩 방식으로 활용하기 때문에, 기본적으로 키에 한글 등을 사용할 수 있지만 가능하면 아스키 범위를 넘지 않는 것이 좋습니다.
그렇지 않으면, 데이터 직렬화/역직렬화 기능을 사용할 때 키와 멤버 변수를 직접 이어주도록 코드를 작성해야하는 번거로움이 있을 수 있습니다
*직렬화, Serialization: JSON 으로 구성된 데이터를 프로그래밍 언어가 제공하는 클래스, 맵, 리스트 등의 객체로 변환해주는 기능. 그 반대를 역직렬화, Deserialization 이라고 한다.
8.3. JSON 메시지 읽고 쓰기
JSON 파일 만들기
JSON 메시지를 만들 때 주의할 점
실무에서는 null 을 사용하지 않는 것이 좋습니다. 어떤 키가 null 을 가리키고 있다면, 실제로 그 키가 어떤 형태의 데이터를 담고 있는지 알 수 없기 때문입니다. 따라서, 빈 값에 준하는 값으로 메시지를 쓰는 것이 좋습니다. 가령, 숫자는 0을, 문자열은 ""(빈문자열)을, 객체는 {}, 배열은 [] 을 할당하여 해당 값이 비어있음을 표현합니다.
8.4. JSON의 한계
불필요한 트래픽 오버헤드
프로토콜 버퍼 형식의 메시지 규격과 비교하여, 불필요한 트래픽 오버헤드가 발생합니다.
- 자체적으로 큰 용량
- 압축시 CPU 자원 사용
메시지 호환성 유지 어려움
클라이언트, 서버 사이에 서로 다른 규격의 JSON 을 사용할 여지가 있고, 이를 해결하기 위해서는 JSON 의 속성에 version 을 명시하거나, RESTful API 에서 해당 API 에 버전을 넣을 수 있습니다.
이를 해결하기 위해 '인터페이스 코드(11장 프로토콜 버퍼)'를 활용할 수 있습니다. 이로써, 컴파일 단계에서 인터페이스를 검증할 수 있습니다.
9. YAML
9.1. YAML 특징
UTF-16 지원
UTF-8 뿐만 아니라 UTF-16 인코딩을 지원합니다. 따라서, Java, Windows 등 UTF-16 기반 시스템에서 설정파일로 활용할 수 있습니다.
주석지원
주석을 지원합니다. 특히 설정파일같은 구조화된 데이터에 설명을 추가할 때 주석은 유용합니다.
앵커와 별칭
한 곳에서 정의한 변수를 여러 곳에서 참조할 수 있는 것처럼, 특정 구조를 앵커로 지정하고, 이를 별칭으로 가져다가 재활용할 수 있습니다.
9.2. YAML 구조
* YAML 에서는 탭문자를 지원하지 않습니다.
9.5. 앵커와 별칭
앵커(anchor)는 & 로 식작하는 식별자를 의미하며, 별칭(alias)은 *로 시작하는 식별자를 의미합니다.
앵커와 별칭을 활용하여 배포 환경에 따른 설정 파일을 구성할 수 있습니다.
<< 키워드를 사용하여 기존 값을 덮어쓰거나, 추가 key 를 할당할 수 있습니다.
9.6. 마치며
YAML 파일에는 악성코드가 포함될 수 있으므로, 외부에서 가져온 YAML 파일이라면, 안전하게 열 수 있는 방법을 고민해야합니다.
10. XML
XML 이 사용되는 곳, 알아두어야 할 필요성
- AWS 에서 제공하는 상당수의 RESTful API 는 응답 형식이 모두 XML 임
- MS 워드, 엑셀 파일은 모두 XML 파일을 압축한 파일임
XML 과 문자열 인코딩
XML 에서는 문자열 인코딩을 직접 지정할 수 있습니다
XML 에서의 NULL 태그
<null_tag />XML 에서의 배열 구조
XML에서는 다음 코드의 element 같이 반복되는 동일한 식별자를 iterator 라고 합니다. 팀에서 반복자는 그 때 그 때 정의하기보다는, element 처럼 고정해두고 쓰는 편이 좋습니다.
10.3. XML 메시지 읽고 쓰기
XML 부분읽기
XML 에서는 파일의 부분만을 읽는 것이 가능합니다. (JSON, YAML 은 파일 전부를 메모리에 로드해야만 함)
XML 헤더
XML 에는 항상 헤더를 추가해주는 것이 좋습니다. XML 헤더는 필수는 아니지만, 버전과 인코딩을 명시해줌으로써, 유지보수 측면에서 유용할 수 있습니다.
<?xml version="1.0" encoding="UTF-8"?>11. 프로토콜 버퍼
프로토콜 버퍼(protocol buffers, protobuf)는 구글에서 만든 데이터 직렬화 규격입니다. JSON, YAML, XML 이 텍스트 기반 규격이라면, 프로토콜 버퍼는 바이너리 기반 규격이기에 더 빠르고 효율적인 데이터 가공 및 처리가 가능합니다.
11.1. 프로토콜 버퍼의 특징
바이너리 규격
프로토콜 버퍼는 바이너리 형태로 데이터를 가공해 저장된 메시지나 파일을 사람이 읽을 수 없습니다. 또한, 바이너리 데이터라고 해서 암호화가 되어있는 것은 아니며, 프로토콜 버퍼 컴파일러에 의해 변경된 인터페이스 코드를 통해서만 사람이 읽을 수 있는 형태로 변환됩니다.
그럼에도 불구하고, 적은 용량, 빠른 처리속도가 장점입니다.
(본 장은 대부분 실습으로 구성되어 있어 따로 정리하지 않습니다.)
12. Base64
- 바이너리 데이터를 아스키 코드의 일부(64개)와 일대일로 매칭되는 문자열로 단순 치환하는 인코딩 방식
- 기존 데이터보다 길이가 1/3(약 33%)만큼 증가
- 바이너리 데이터를 문자열 기반 데이터로 취급해야하는 곳에서 사용
12.2. Base64 인코딩 구현
💡 책의 예제(json 파일을 파이썬 코드로 Base64 로 인코딩하기)와는 다르게, 8x8 png 파일을 불러와 Base64 로 변환하는 과정을 진행해봅니다.


NodeJS 스탠다드 라이브러리 활용
readFileSync 함수는 읽어들인 파일을 Buffer 객체로 반환합니다.
Buffer 객체의 toString() 함수는 인자로 인코딩 방식을 지정할 수 있고, 'base64' 를 입력하여 base64 인코딩된 문자열을 출력합니다.
yoshi.png 파일을 base64 방식으로 인코딩한 결과: 292 bytes (133.33 %, 정확히 1/3 증가)
iVBORw0KGgoAAAANSUhEUgAAAAgAAAAICAYAAADED76LAAAAAXNSR0IArs4c6QAAAJVJREFUKFNjZGBg+M/AwMBwWV+fYccUaYaDb9gY7EV+MZTabgMJMzCCFMAkQYLdh73AEjAAVgDifPzxEiw263QipgKQCXInd+FWAHPD6fx8huAob7gJ/BziDIw+6wP+tzfcZ6hsUARLBL33A9PrBDcxbAncAHGkz/oAsMtBPkBWAPcFzAoQrXvxIkOW9CywKdOepjEAAJjrOBTd2vUfAAAAAElFTkSuQmCC
donald.png 파일을 base64 방식으로 인코딩한 결과: 280 bytes (134.61%, 약 1/3 증가 - 패딩문자가 포함되었기 때문)
iVBORw0KGgoAAAANSUhEUgAAAAgAAAAICAYAAADED76LAAAAAXNSR0IArs4c6QAAAIpJREFUKFNjZGBg+M+ABJyWfgXz9kVzg2lGFAUJKQz/Z9TClTNyyKMpAKn+8ZABJAGjUU0AKZiBbCGSFTC7J3ZZMehevIiw5vGnv2BHxm/+wbDQl4OhLj+F4cCBAwwGPO0M6y9HQNzw+NNfsI5bpw+AaWdnZ4QJ/2dAvMmYwcAQ62CO4oDFB04yAACr0jGYHLmygQAAAABJRU5ErkJggg==
Base64 인코더 동작 원리 확인
Base64 인코딩이 실제로 어떻게 이루어지는지 수동으로 확인해봅니다.
위 donald.png 파일의 앞 3byte 만큼의 데이터를 가지고 이것이 실제로 Base64 로 인코딩된 결과의 맨 앞 4글자 `iVBO` 와 일치하는지 확인해봅니다.
먼저, 다음 코드로 파일데이터가 어떻게 표현되는지 살펴봅니다.
Buffer.toString() 함수는 파일 데이터를 단순히 16진수로 표현해주고 있음을 확인할 수 있습니다.
(Buffer 의 각 요소는 리스트 접근자([])로 접근할 수 있습니다.)
Buffer 의 맨 앞 3byte 를 2진수로 추출합니다.
추출한 2진수를 다시 쓰면 다음과 같습니다. 그리고 6자리씩 색깔로 구분하여 끊어보았습니다.
10001001 01010000 01001110
이를 다시 6자리로 끊어주면 다음과 같이 표현할 수 있습니다.
100010 은 10진수로 34 이며 이는 아스키 문자 i 에 해당합니다.
010101 은 10진수로 21 이며 이는 아스키 문자 V 에 해당합니다.
000001 은 10진수로 1 이며 이는 아스키 문자 B 에 해당합니다.
001110 은 10진수로 14 이며 이는 아스키 문자 O 에 해당합니다.
즉 순서대로 `iVBO` 가 되는 것을 확인할 수 있습니다.
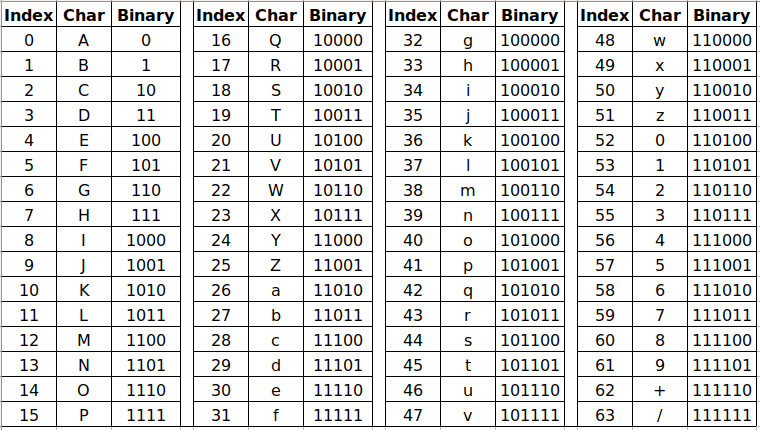
위 원리를 기반으로 프로그래밍적인 방식으로 base64 인코더를 구현할 수 있습니다.
Base64 인코딩 방식에서 패딩문자(=, ==)가 필요한 이유
base64 는 말 그대로 64(2의 6제곱) 개의 문자들로 데이터를 표현하기 위한 인코딩 방식입니다. 따라서 base64 인코딩된 하나의 문자는 6 bit 를 필요로 합니다. 그러나, 보통의 데이터세계에서는 데이터의 기본 단위가 8 bit 가 모인 1 byte 입니다. 따라서, byte 단위 데이터를 6bit 로 남김없이 채우기 위해서는 데이터의 크기가 3 byte (=24 bit)의 배수이어야만 합니다.
즉 위 donald.png 파일은 208 bytes 였고, 이는 3의 배수가 아닙니다. 이를 3의 배수로 만들어주기 위해서는 2byte 가 더 필요합니다. 따라서, 이 2byte 를 패딩문자로 채워서 3의 배수를 맞춰줍니다.
반면, yoshi.png 파일은 219 bytes 이고, 이는 정확히 3의 배수입니다. 따라서 패딩 문자가 필요하지 않습니다.
데이터 길이를 명시적으로 구분 가능한 JSON 값이나 HTTP body 부분에서는 패딩문자가 반드시 필요하지는 않지만, TCP 통신에서 byte 단위의 네트워크 스트림에서 패딩 문자가 없다면, 의도하지 않은 데이터블록이 생성될 수 있기 때문에 (데이터 길이가 명시되지 않은 상태라면) 패딩문자를 포함하여 데이터 블록의 끝을 명시해줌으로써, 서로 분리되어야 하는 데이터 블록을 구분할 수 있습니다.
12.3. Base64 디코딩 구현
Base64 인코딩에서 진행했던 과정을 그대로 되돌리면, 원본 데이터를 얻어낼 수 있습니다.
- Base64 로 인코딩된 문자열을 6bit 2진수로 변환(base64 테이블)하여 연결(concat)합니다.
- 1. 에서 얻어진 문자열을 8bit 단위로 끊어 16진수로 변환한 뒤, 이를 buffer 에 할당합니다.
NodeJS 스탠다드 라이브러리 활용
Base64 디코딩시 주의할 점
원본 데이터 타입 명시, 데이터 길이 명시 또는 패딩문자 포함
(요즘에는 동영상 스트리밍과 같이 실시간으로 데이터를 주고 받는 경우 base64 를 쓰는 경우가 드물다. 대신 RTMP, HLS 와 같은 훌륭한 동영상 프로토콜을 사용한다.)
12.5. URL-Safe Base64
Base64 인코딩의 마지막 두 개의 문자는(62번, 63번) 각각 `+`, `/` 이고, 이는 URL 에서 특별한 의미를 가지므로, URL 에 Base64 로 인코딩된 데이터를 포함할 때는 주의해야 합니다.
URL-SafeBase64 는
- + (62번) ➡ -
- / (63번) ➡ _
- = (패딩) ➡ .
으로 대체하여 표현합니다.
12.6. 마치며
HTTP 로 큰 파일을 보낼 때 Base64 로 파일을 인코딩하는 것은 데이터의 크기가 33% 증가하므로, 좋은 방법이 아닐 수 있습니다. 이런 경우 HTTP 멀티파트 기능을 살펴보는게 도움이 될 수 있습니다.
13. 데이터 압축(zlib)
zip 파일을 압축할 때에는 DEFLATE 알고리즘을 사용합니다.
13.1. zip, zlib, DEFLATE, INFLATE
zip 확장자 파일의 의미: DEFLATE 알고리즘으로 압축된 파일을 의미
zlib: DEFLATE 알고리즘으로 파일을 압축할 수 있는 기능을 제공하는 라이브러리 (무료)
INFLATE: 압축을 해제할 때 사용하는 알고리즘
💡 웹소켓, HTTP 프로토콜은 DEFLATE 통신을 기본으로 지원합니다. 브라우저와 Nginx 같은 웹 서버 프레임워크가 알아서 처리해줍니다.
13.2. 압축 시 중요한 요소
압축 원리
- 압축은 데이터의 공통된 부분을 찾아 하나로 묶어 저장하는 행위 (가령 AAAAAAAAAA 을 A10 으로 줄여쓰면 데이터 저장 공간을 줄일 수 있음)
- DEFLATE 알고리즘이 공통된 부분을 찾기 위해 사용하는 알고리즘: L777
- 공통된 부분을 무손실 압축하는 알고리즘: 허프만 부호화
- INFLATE 알고리즘: 압축된 정보로부터 압축을 해제
손실압축 VS 무손실압축
비디오, 오디오, 사진 등의 멀티미디어 데이터는 손실압축을 하더라도, 사람이 압축된 데이터로 표현된 미디어를 감상하는 데 지장이 없을정도로 손실이 미치는 영향이 적다. 이렇게, 손실이 미치는 영향이 적을 때 손실 압축을 활용한다.
무손실압축은 원본을 100% 동일하게 재현해야할 때 활용하는 압축 기술이다. 손실압축에 비해 압축률은 떨어진다. DEFLATE 알고리즘이 대표적이다.
압축률
압축률이 5라면, 10Mb 원본 파일을 2Mb 로 줄이는 것을 의미한다.
일반적으로 압축률이 높으면 압축을 풀기 위해 더 많은 CPU 자원을 사용한다.
압축된 파일의 크기는 압축을 수행하기 전에는 알 수 없다. (손실압축, 무손실압축 모두에 해당)
'압축 레벨'이 높으면 높을수록 더욱 높은 압축률을 의미한다.
'압축 속도'는 압축률과 반비례 관계이다.
'압축 해제 속도'는 일반적으로 '압축 속도'에 비해 월등히 빠르다. '압축'시에는 패턴을 파악하고, 해당 패턴에 최적화된 알고리즘을 적용하는 과정이 포함되는 반면, '압축 해제'시에는 이미 압축할 때 파악한 패턴을 활용하여 복원만 하면 되기 때문이다.
체크섬
checksum 은 바이너리 데이터로부터 추출하여, 원본 데이터의 유실 여부, 변조 여부를 확인하는 데 활용된다.
해시함수인 MD5, SHA-1, SHA-2 와 비교와 비슷한 기능을 수행하지만, 그렇다고 해시 알고리즘은 아니다. 나열된 해시 알고리즘들보다 매우 빠른 속도로 값을 만들지만, 해시함수의 기능은 갖고 있지 않다. 단순히 데이터의 유실 및 변조 여부만 확인할 수 있다.
13.3. 파일 압축 예제
python 에서 zlib 라이브러리를 활용하여 파일 압축 및 해제를 실습해봅니다.
실무에서 압축 기능 사용시 확인해야할 사항들
- 실제 사용할 데이터를 가지고 압축률과 압축시간을 비교한 뒤 적절한 압축레벨을 설정한다.
- 압축률을 높이기 위해 불필요하게 시간을 많이 사용할 필요는 없다.
- 압축률, 압축시간은 데이터의 길이, 패턴 등에 따라 다르므로, 직접 비교를 통해서만 파악이 가능하다.
- TCP 보다 낮은 수준에서 데이터를 주고받는 경우(가령 UDP 처럼 무결성을 보장하지 않거나 일부 데이터가 훼손될 가능성이 있는 경우) CRC32 값으로 데이터의 무결성을 검증한다.
- 웹, 서버 간 주고 받는 메시지를 압축하는 경우 TCP 단계에서 무결성을 검증하기 때문에 별도의 무결성 확인을 진행할 필요는 없다.
- ADLER32 는 CRC32 와 비슷하지만 더 빠른 체크섬 방식이다.
- 이 두 방식은 암호학적으로 안전하지 않기 때문에, 무결성 검증 이외의 용도로는 사용해서는 안된다.
13.5. 마치며
- 모든 크기의 데이터가 압축될 필요는 없다!
데이터 크기가 가변적인 경우, 특정 크기 이상의 데이터에 대해서만 압축하게 하는 것이 좋습니다. 개발환경에서 압축 효율이 높아지는 데이터 크기를 미리 알아낸 다음, 해당 크기 이상인 데이터의 경우에만 압축하도록 설정하는 것이 좋습니다. - DEFLATE 를 지원하지 않는 브라우저가 있을 수 있다!
DEFLATE 알고리즘을 지원하지 않는 브라우저가 있을 수 있으므로, 일반적으로는 Nginx 와 같은 웹 서버가 알아서 처리하겠지만, Http 서버에서 항상 DEFLATE 를 사용하지 않게 설정해두는 것이 좋습니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
'개발 서적' 카테고리의 다른 글
| 학교에서 알려주지 않는 17가지 실무 개발 기술 15장 (0) | 2022.08.25 |
|---|---|
| 학교에서 알려주지 않는 17가지 실무 개발 기술 14장 (0) | 2022.05.07 |
| 학교에서 알려주지 않는 17가지 실무 개발 기술 Part1 (0) | 2021.11.07 |
| 앱 highlight 떠나보내주기: 책 속에 밑줄 긋기 (0) | 2021.11.04 |
| 책장 파먹기 (0) | 2021.11.01 |